工作中,,如何用python和selenium提取驗(yàn)證碼?
根據(jù)以往的經(jīng)驗(yàn),,有四種方法:
讓開(kāi)發(fā)人員幫助刪除驗(yàn)證碼,,并重新部署環(huán)境以獲得通用驗(yàn)證碼。每次登錄都可以登錄,,使用cookie添加登錄名和密碼,,避開(kāi)驗(yàn)證碼??梢岳侠蠈?shí)實(shí)的拿到驗(yàn)證碼圖片,,識(shí)別驗(yàn)證碼。
方法1:
說(shuō)到輕松開(kāi)發(fā),,他一般都能幫忙去掉驗(yàn)證碼的代碼,。
但是去掉代碼后,需要重新部署一套沒(méi)有驗(yàn)證碼的環(huán)境,,比較麻煩,,不推薦。
方法二:
還是需要開(kāi)發(fā)的幫助,,得到一個(gè)通用的驗(yàn)證碼,,但是測(cè)試環(huán)境做出的通用驗(yàn)證碼永遠(yuǎn)到不了正式環(huán)境。
所以不建議。還是先想想別的辦法吧,。
方法三:
這種方法的難點(diǎn)是如何在cookie中找到登錄用戶名和密碼的名稱,,然后添加用戶名和密碼。
方法4:
最容易想到的方法,,重點(diǎn)看這個(gè)方法,,這里有兩個(gè)思路。
對(duì)登陸頁(yè)面進(jìn)行截圖,,然后抓取驗(yàn)證碼圖片進(jìn)行識(shí)別,;直接在登錄頁(yè)面,定位驗(yàn)證碼,,將驗(yàn)證碼圖片另存為并識(shí)別,;
該方法實(shí)現(xiàn)過(guò)程中使用了第三方庫(kù)pytesseract,所以要引用的庫(kù)要先安裝,。

Pyseract依賴于pytesseractt,,需要先安裝pytesserac。
安裝宇宙魔方模塊:
Git文件地址:https://digi.bib.uni-mannheim.de/tesseract/
請(qǐng)安裝沒(méi)有開(kāi)發(fā)的穩(wěn)定版本,。下載后是一個(gè)exe安裝包,。只需右鍵點(diǎn)擊安裝即可。
通常,,它安裝在默認(rèn)路徑中,。如果不在默認(rèn)路徑中,請(qǐng)記住路徑,。
下載培訓(xùn)數(shù)據(jù):
如果需要下載相應(yīng)的訓(xùn)練數(shù)據(jù),,直接下載整個(gè)zip文件,解壓后將文件復(fù)制到‘Tess data’目錄,。
一般為:c : program files(x86) tesserac-ocr Tess data

配置環(huán)境變量:
編輯系統(tǒng)變量中的路徑并添加安裝路徑:c : program files(x86) tesserac t-OCR,。添加值為c : program files(x86) tesserac-OCR Tess data的TESSDATA_PREFIX變量。最后,,在cmd命令模式下測(cè)試安裝是否成功
安裝python的第三方庫(kù):
安裝Pillow #一個(gè)python圖像處理庫(kù),,依賴于pytesseract。
pip安裝pytesseract
修改pytesseract.py文件:
找到pytesserac的安裝包,,c : python 34 lib site-packages pytesserac,。
編輯pytesseract.py文件。這一步必須完成,,否則編譯時(shí)會(huì)報(bào)錯(cuò),。
修正案如下:
tessera CT _ cmd=' c :/Program Files(x86)/tessera CT-OCR/tessera CT . exe '

上面已經(jīng)描述了這兩種實(shí)現(xiàn)思路,現(xiàn)在分別說(shuō)明代碼實(shí)現(xiàn)過(guò)程,。
想法一:
首先計(jì)算瀏覽器與登陸頁(yè)面截圖的比例值,,然后計(jì)算對(duì)應(yīng)的驗(yàn)證碼圖片位置,,進(jìn)而得到驗(yàn)證碼圖片。二值化后的圖像通過(guò)pytesseract庫(kù)進(jìn)行轉(zhuǎn)換,。
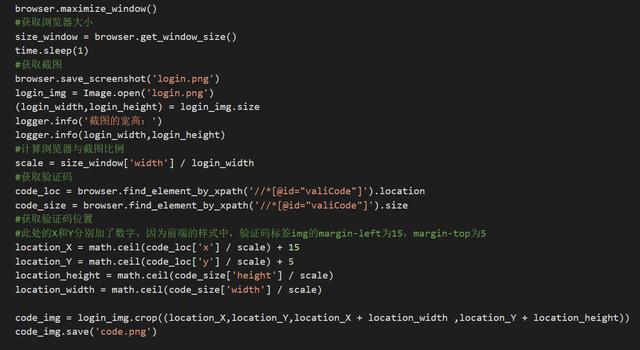
保存截圖驗(yàn)證碼
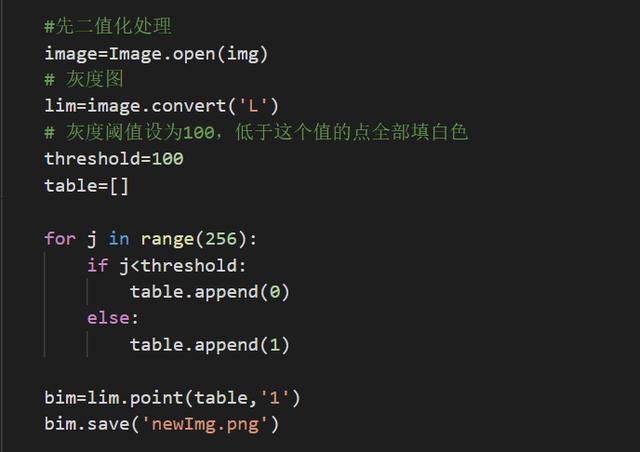
二進(jìn)制處理驗(yàn)證碼圖片
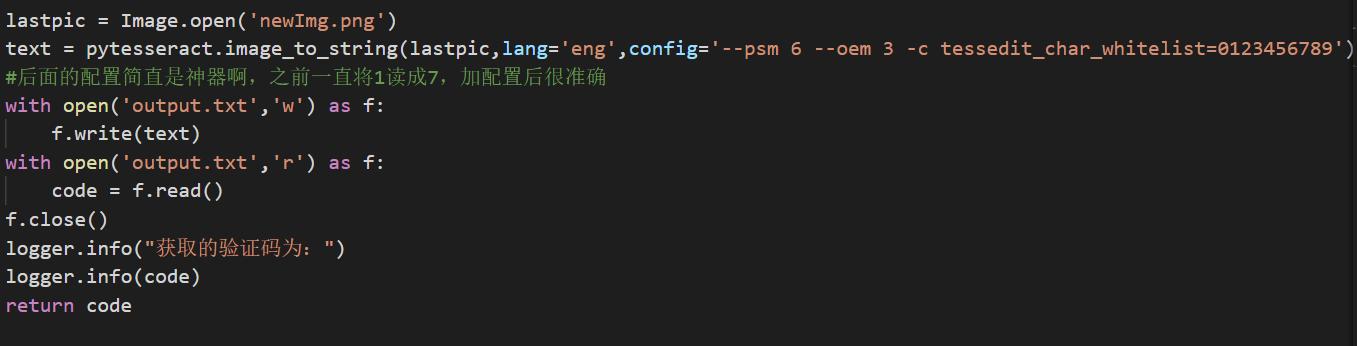
驗(yàn)證碼圖像轉(zhuǎn)換
注意以上圖像轉(zhuǎn)換過(guò)程中的參數(shù)設(shè)置,。
未設(shè)置參數(shù)時(shí),1會(huì)一直轉(zhuǎn)換為7,,設(shè)置后轉(zhuǎn)換精度會(huì)下降,。
當(dāng)然目前只是數(shù)字型的驗(yàn)證碼,文字型的方法應(yīng)該差不多,。
想法二:
首先定位驗(yàn)證碼的位置,將驗(yàn)證碼圖片保存為路徑,。從這個(gè)路徑,,獲取最新的驗(yàn)證碼圖片。驗(yàn)證碼圖片的二值化圖像由pytesseract庫(kù)轉(zhuǎn)換,。
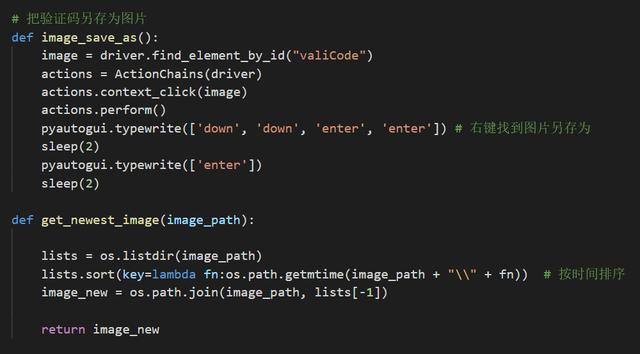
將驗(yàn)證碼保存為圖片
接下來(lái)的圖像處理和獲取驗(yàn)證碼的過(guò)程和第一個(gè)思路一樣,。
官方微信
TOP